
Le contexte est roi
Quand je montre le résultat d’une tâche réalisée avec Claude Code, ou un audit de code généré en quelques minutes, on me pose souvent la même question : “C’était quoi ton prompt ?”.
Je le partage volontiers. Mais j’insiste à chaque fois sur un point : le prompt, c’est le truc le moins important de toute la chaîne.
Context engineering : l’idée qui change tout
On entend beaucoup parler de “prompt engineering”. Comment formuler la requête parfaite, la bonne structure, les bons mots-clés, les bons exemples. Il existe des formations entières dédiées au sujet, des certifications, des postes LinkedIn de “prompt engineer”.
Mon expérience quotidienne ne valide pas cette approche. Ce qui sépare un résultat médiocre d’un résultat excellent, ce n’est jamais la formulation du prompt. C’est le contexte dans lequel il est envoyé.
D’où l’idée de “context engineering”. L’idée est simple : si le modèle dispose des bonnes informations au bon moment, il comprendra l’intention même si le prompt est approximatif, bourré de fautes, écrit à la va-vite entre deux meetings. À l’inverse, le prompt le plus élaboré du monde ne produira rien de bon si le modèle ne sait pas de quoi on parle.
Ça change complètement la façon de voir les choses. On arrête de se demander “comment bien formuler ma demande ?” pour se demander “est-ce que le modèle a tout ce qu’il lui faut pour comprendre ce que je veux ?”.
Parler au LLM comme à un nouveau collègue
Le déclic, pour moi, a été de traiter le LLM comme un développeur qui vient de rejoindre l’équipe. Quelqu’un de compétent techniquement, mais qui ne connaît rien au projet.
Quand un nouveau dev arrive, personne ne lui balance un ticket Jira en disant “tiens, fais ça”. On prend le temps. On explique le contexte métier, l’architecture du projet, les conventions de l’équipe, les pièges connus. On montre où trouver la doc, quels fichiers sont importants, comment lancer les tests.
Avec Claude Code, c’est pareil.
Avant d’attaquer un développement, je pose le cadre. J’explique le domaine fonctionnel, ce qu’on cherche à résoudre, et surtout pourquoi. Je ne donne pas juste un bout de code à modifier. Je donne le contexte métier autour.
Claude Code offre des mécanismes concrets pour ça. En tapant @, on accède à une recherche par nom de fichier qui permet de référencer directement n’importe quel fichier du projet dans le prompt. Je m’en sers pour pointer vers les fichiers clés : documentation technique, ADR (Architecture Decision Records), tests fonctionnels qui décrivent le comportement attendu.
Sur mon projet actuel, on utilise Behat, et les scénarios Gherkin sont une mine d’or pour le modèle. Il lit du “Given I create a user / When I update table X / Then the status should be active” et il comprend immédiatement le métier sans que j’aie besoin de rédiger une spécification.
Je donne aussi les noms des classes que je pense pertinentes, les services existants, les conventions spécifiques du projet. Plus le modèle a de contexte métier, moins la formulation du prompt a d’importance.
Le plan mode : là où tout se joue

Si je ne devais garder qu’un seul outil dans Claude Code, ce serait le plan mode.
Le principe : avant de lancer le premier prompt, on bascule dans un mode dédié à la planification (Shift+Tab pour basculer). Le modèle consacre toute son énergie à explorer le projet et comprendre les dépendances avant de poser un plan d’implémentation structuré. Pas de code à ce stade. Juste de la réflexion.
C’est pendant cette phase que le contexte se charge. J’explique le besoin en détail, je référence les fichiers importants avec le @, je pointe vers les tests unitaires et fonctionnels concernés. Le modèle lit, analyse, et part de lui-même explorer des fichiers connexes que je n’avais pas identifiés.
Le vrai intérêt du plan mode, c’est le dialogue qui s’installe. Le modèle pose des questions, challenge mes choix, pointe des ambiguïtés que je n’avais pas vues. Sur les gros tickets, je passe facilement une heure à itérer avec lui. Tant que le plan ne me convainc pas complètement, je continue de challenger.
Une fois le plan validé, Claude Code propose de repartir sur une session fraîche. Ça peut sembler contre-intuitif de tout effacer alors qu’on vient de passer du temps à discuter. Mais le plan est sauvegardé avec toutes les informations nécessaires, et un contexte vierge libère l’intégralité des tokens disponibles pour l’implémentation.
Gérer sa fenêtre de contexte
Un LLM n’a pas de mémoire au sens classique. Sa “mémoire de travail”, c’est sa fenêtre de contexte : un espace à taille fixe dans lequel rentre tout ce qu’on lui envoie. Les instructions persistantes (CLAUDE.md), les définitions de commandes et skills, les outils MCP, l’historique complet de la conversation.
Quand cette fenêtre est pleine, le modèle ne peut plus travailler. Il faut alors la nettoyer pour pouvoir continuer. Apprendre à gérer cette ressource, c’est aussi important que de savoir poser un bon contexte initial.
Claude Code fournit plusieurs commandes pour ça, et elles rythment mes journées de travail.
/compact résume la conversation pour libérer de la place. Le modèle condense les échanges, garde l’essentiel, et repart avec un contexte allégé. Détail utile : la commande accepte des instructions optionnelles (/compact garde le plan d'implémentation et les fichiers modifiés) pour orienter ce que le modèle doit préserver pendant le résumé. Par défaut, cette compaction se déclenche automatiquement quand le contexte atteint un certain seuil. Du coup, j’ai désactivé cette automatisation (via le paramètre autoCompact dans les réglages de Claude Code). Je préfère choisir moi-même le bon moment, parce que le timing compte : compacter entre deux tâches distinctes, ça va. Compacter au milieu d’une implémentation complexe, c’est perdre des détails critiques.
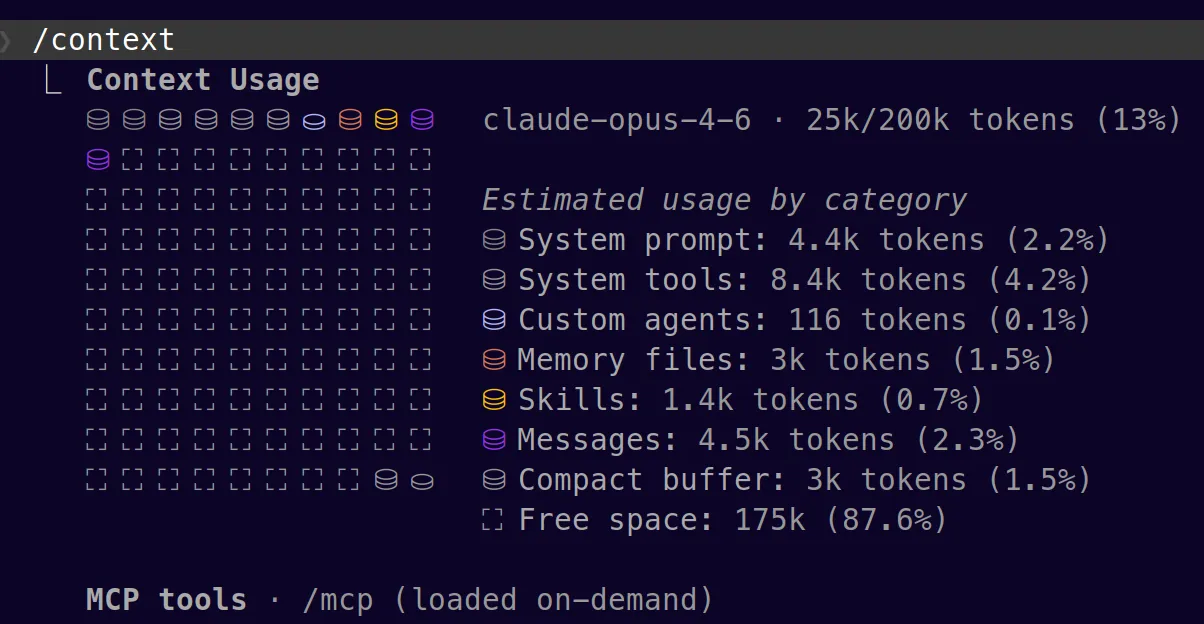
Bref, pour ne pas être pris au dépourvu, j’affiche en permanence le pourcentage de contexte utilisé grâce à la status line de Claude Code. Quand j’approche des 90%, je sais qu’il est temps de compacter ou de repartir de zéro. Lancer une tâche avec un contexte quasi-plein, c’est s’assurer que le modèle ne pourra pas aller au bout. Pour un diagnostic plus détaillé, /context affiche ce qui occupe la fenêtre et combien chaque élément consomme.
/rewind permet de revenir en arrière dans la conversation. Si le modèle part dans une mauvaise direction, au lieu de corriger en empilant du contexte inutile, je rembobine. Le modèle oublie tout ce qui vient après, et le code est restauré à son état précédent. C’est le Ctrl+Z de la collaboration avec l’IA. C’est aussi la porte de sortie quand le contexte est tellement saturé que même /compact ne fonctionne plus : on revient en arrière pour retrouver de la marge.
/resume reprend une session précédente avec tout son historique. Quand la QA revient avec des modifications sur un développement livré la veille, je ne réexplique pas tout depuis le début. Je recharge la session d’origine et le modèle retrouve immédiatement le contexte du sujet.
/clear repart de zéro. Indispensable entre deux sujets complètement différents, pour ne pas polluer une nouvelle tâche avec les résidus de la précédente.
Ces commandes, combinées au plan mode, constituent l’ossature de mon workflow quotidien. Au final, c’est en les maîtrisant que j’ai pigé un truc : le temps passé à gérer le contexte rapporte bien plus que le temps passé à peaufiner un prompt.
Et le prompt dans tout ça ?
Honnêtement ? Je ne fais aucun effort dessus.
Si le contexte est bien chargé, si le plan mode a fait son travail, si les bons fichiers ont été référencés, le prompt peut être une phrase jetée à la va-vite. Avec des fautes, des abréviations, du franglais. Le modèle comprend.
Je prompte comme je pense à voix haute. Je balance mes idées en vrac, sans les structurer. Et surtout, je laisse mes hésitations telles quelles dans le prompt : “je suis pas sûr, j’hésite entre ces deux approches”, “finalement je ferais plutôt comme ça, ou peut-être pas”. Ce n’est pas du bruit. C’est du signal. Le modèle identifie les points d’incertitude et va naturellement creuser ces zones, challenger mes doutes, proposer des alternatives là où je suis flou.
C’est l’inverse exact du “prompt engineering” classique où chaque mot est pesé et calibré. Avec un bon contexte, la précision du prompt devient secondaire. L’intention suffit.
Et après ?
Tout ce que j’ai décrit repose sur un socle que j’ai à peine mentionné : les fichiers d’instructions persistantes. Dans Claude Code, ce sont les fichiers CLAUDE.md, chargés automatiquement à chaque interaction. Ils constituent la base permanente du contexte, ce que le modèle sait avant même qu’on lui dise quoi que ce soit.
Que mettre dedans, comment les structurer, comment les organiser entre le global et le spécifique projet, il y a largement de quoi dire. Justement, ce sera l’objet du prochain article de la série.